Prerequisites
- The CLI installed — see Install.
- Interactive shell from container (Docker only) — see Run interactively.
- A model pulled.
geniex servedoes not auto-download models.
Start the server
Pull a model:bash
bash
http://127.0.0.1:18181 by default. Keep this terminal open and make requests from another one. Run geniex serve -h for all configurable options.
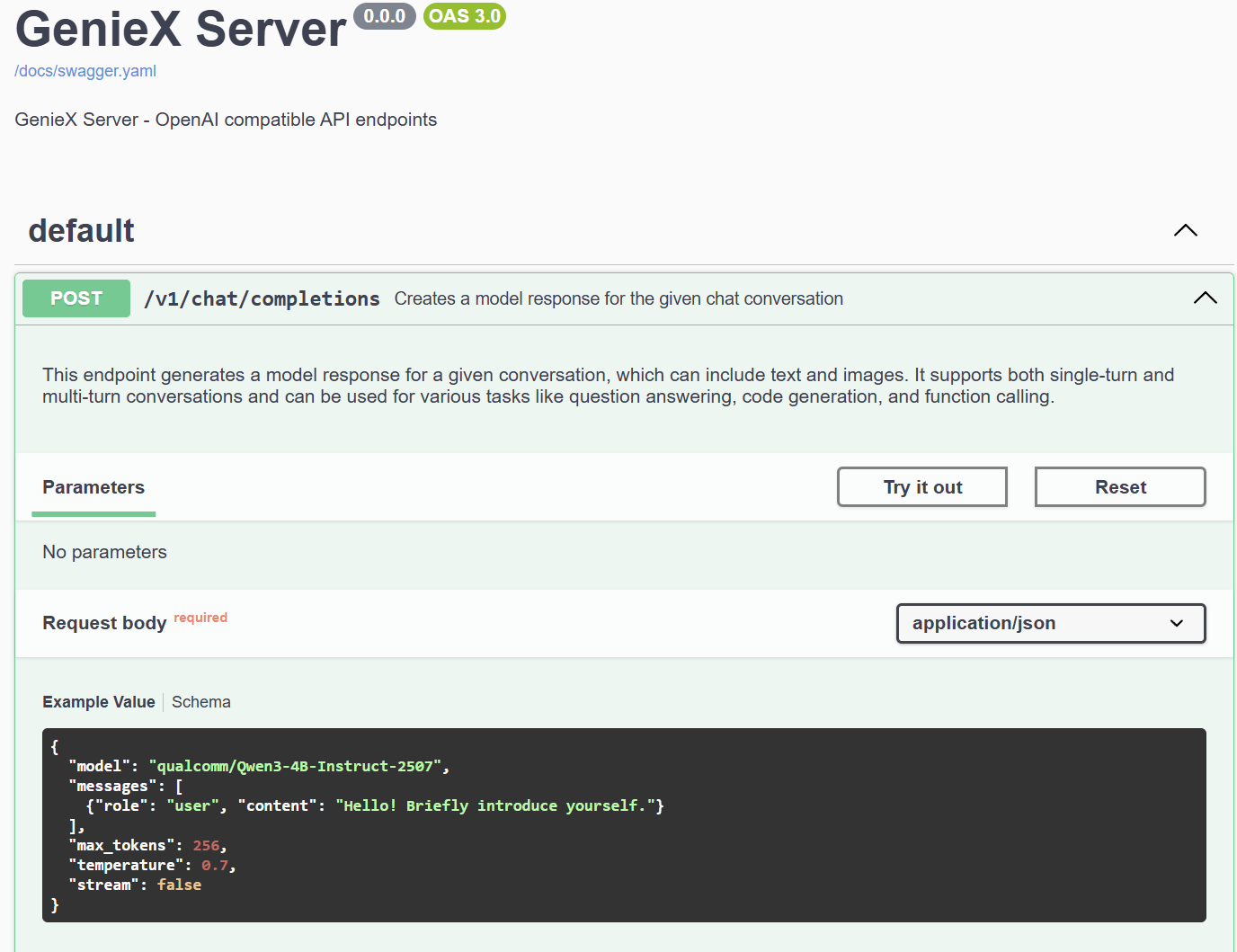
POST /v1/chat/completions
Creates a model response for a conversation. Supports LLM (text-only) and VLM (image + text).LLM request
Example Value
Try it from Swagger UI
Openhttp://127.0.0.1:18181 in your browser to access the built-in Swagger UI.
Step 1. Expand the POST /v1/chat/completions endpoint to view the example request body and schema.
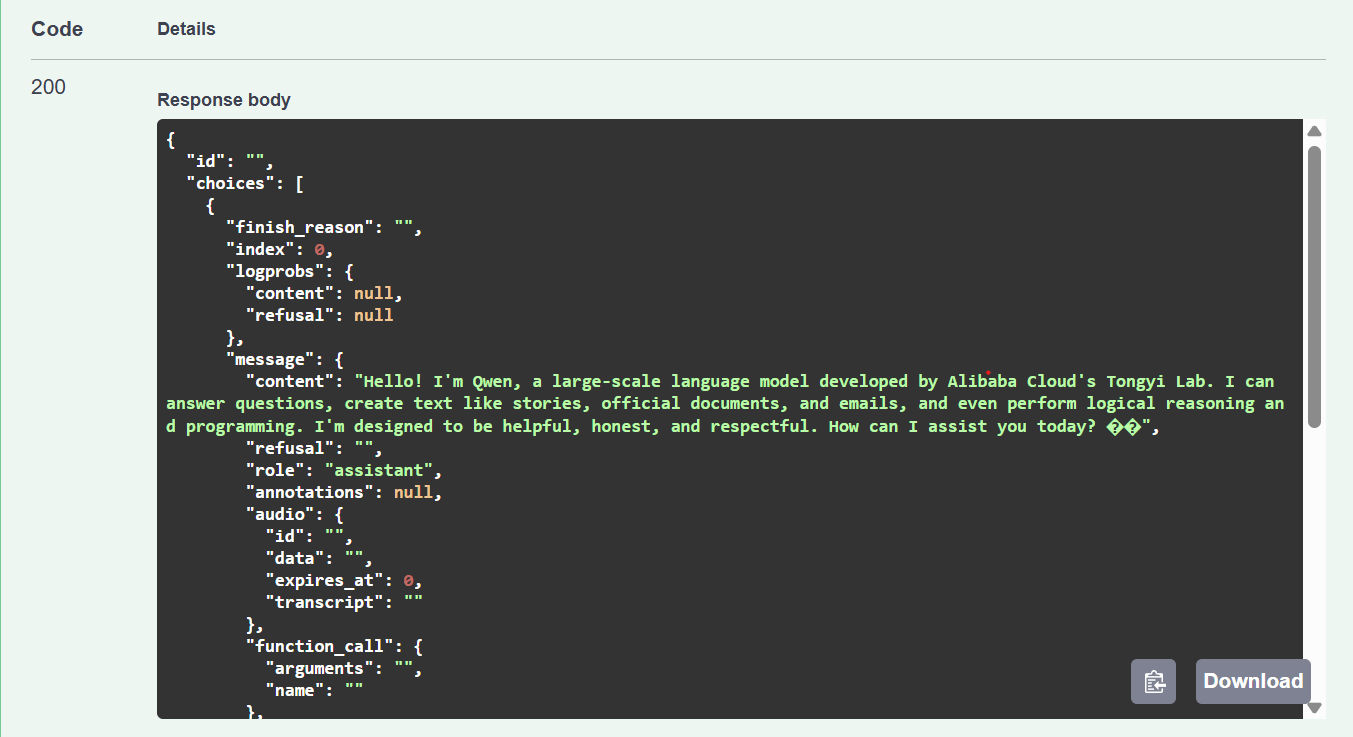
200 status with the model’s generated reply.
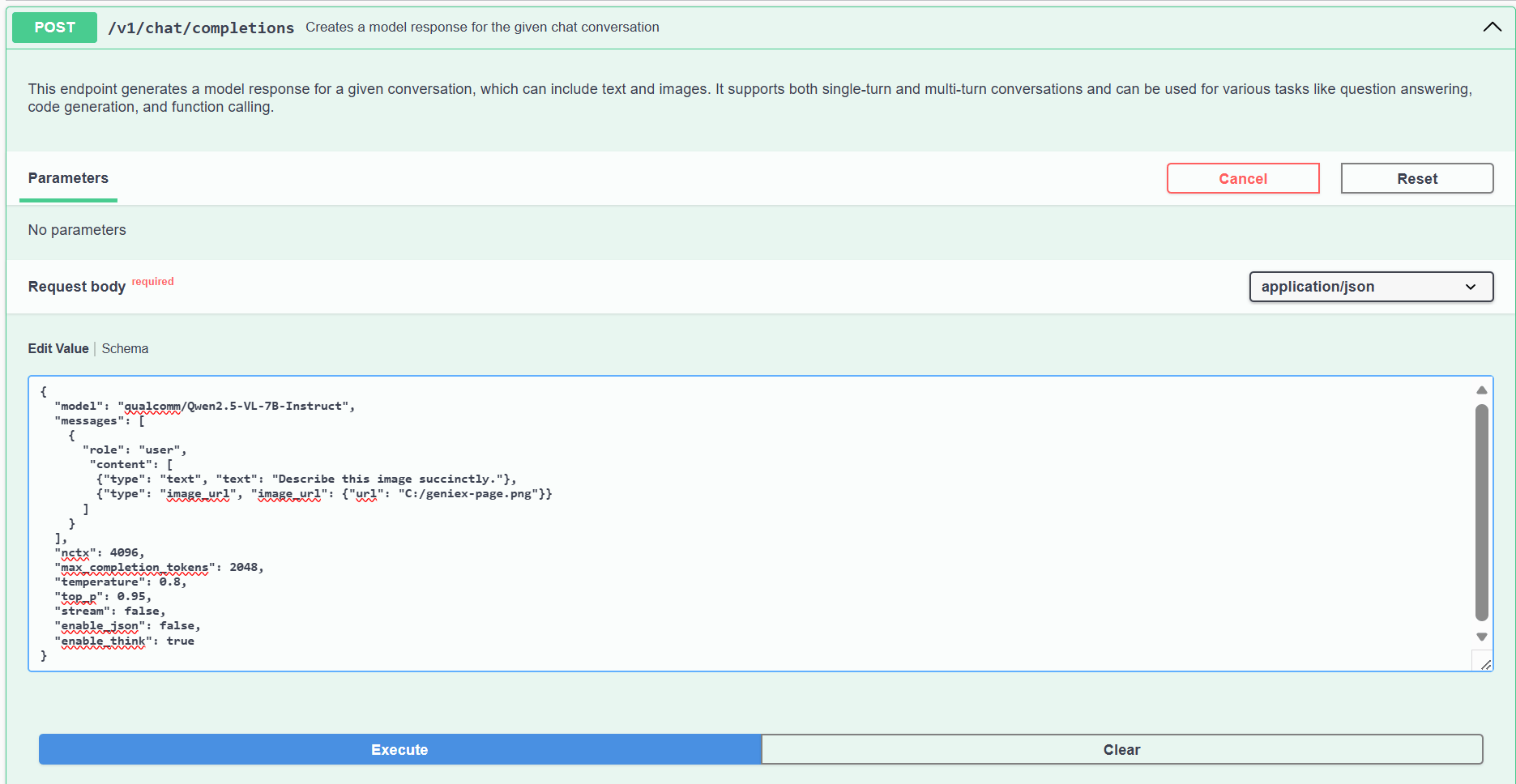
VLM request
image_url.url accepts three formats:
| Format | Example |
|---|---|
Local file path (the file:// prefix is optional) | C:/Users/Username/Pictures/photo.jpg, file:///tmp/photo.jpg |
| HTTP / HTTPS URL — fetched by the server | https://example.com/image.jpg |
| Base64 data URL — inline image bytes | data:image/png;base64,iVBORw0KGgo... |
Running in Docker? Local paths are resolved inside the container, not on your host. The install command already mounts
$PWD/data to /data — drop your images there and pass /data/cat.jpg. Alternatively, use an HTTP URL or base64 data URL to skip the filesystem entirely.Example Value
image_url.url to a local image, then click Execute.
Python client (OpenAI SDK)
Because the server speaks the OpenAI protocol, you can point the officialopenai Python client at the local endpoint and reuse any existing OpenAI code. Install with pip install openai, then:
python
Replace the
model value with a model you have already pulled. The optional :<precision> suffix selects a precision (quantization) variant (e.g. Q4_0, Q4_K_M, Q8_0) — Q4_0 is recommended for llama.cpp on Hexagon NPU. See Precisions (Quantizations) Supported.Other endpoints
GET /v1/models— list available models.GET /v1/models/{model}— get info about a specific model.
Was this page helpful?