前置条件
启动服务器
拉取模型:bash
bash
http://127.0.0.1:18181。保持该终端开启,并在另一个终端中发送请求。运行 geniex serve -h 查看所有可配置选项。
POST /v1/chat/completions
为给定对话创建模型响应。支持 LLM(纯文本)与 VLM(图像 + 文本)。LLM 请求
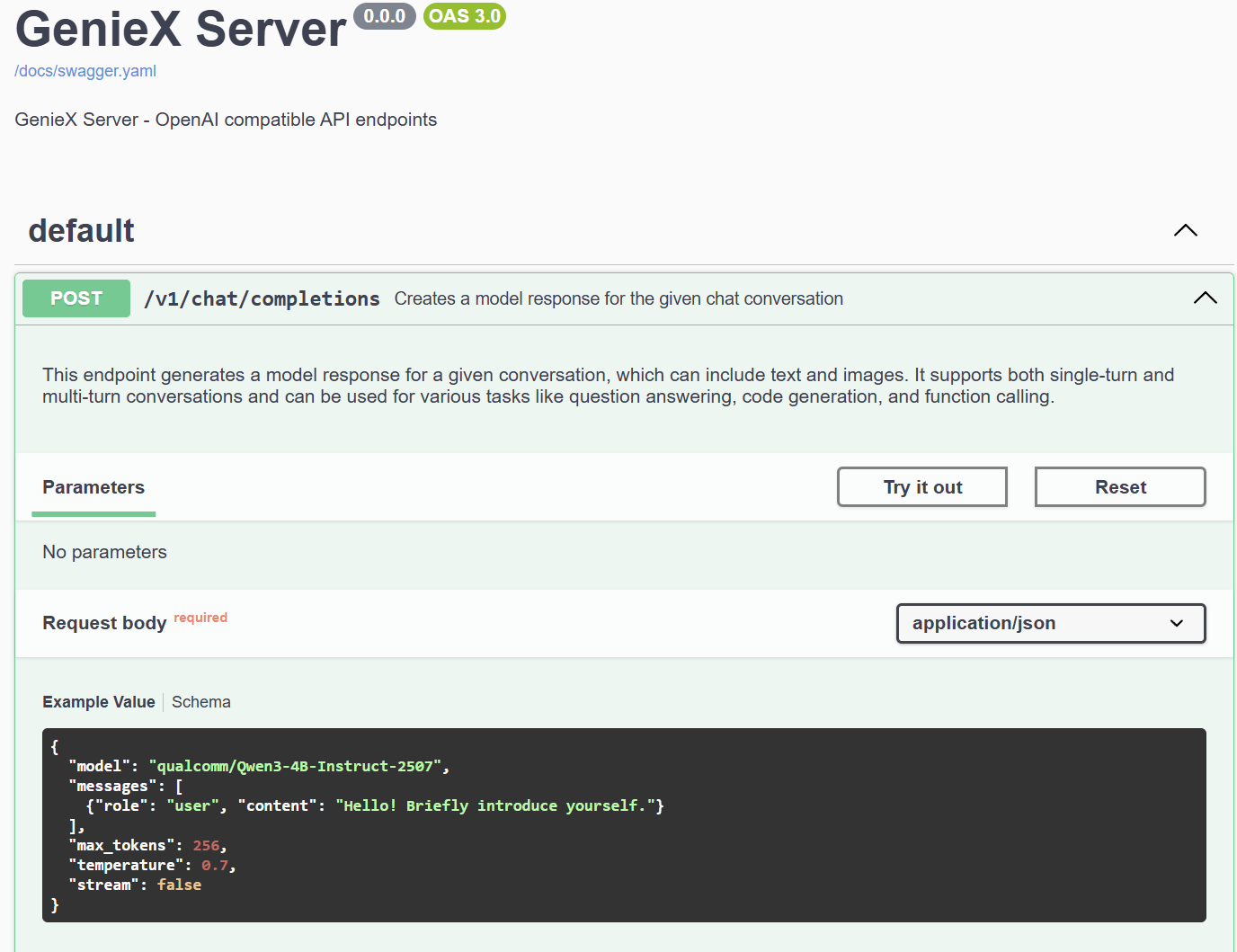
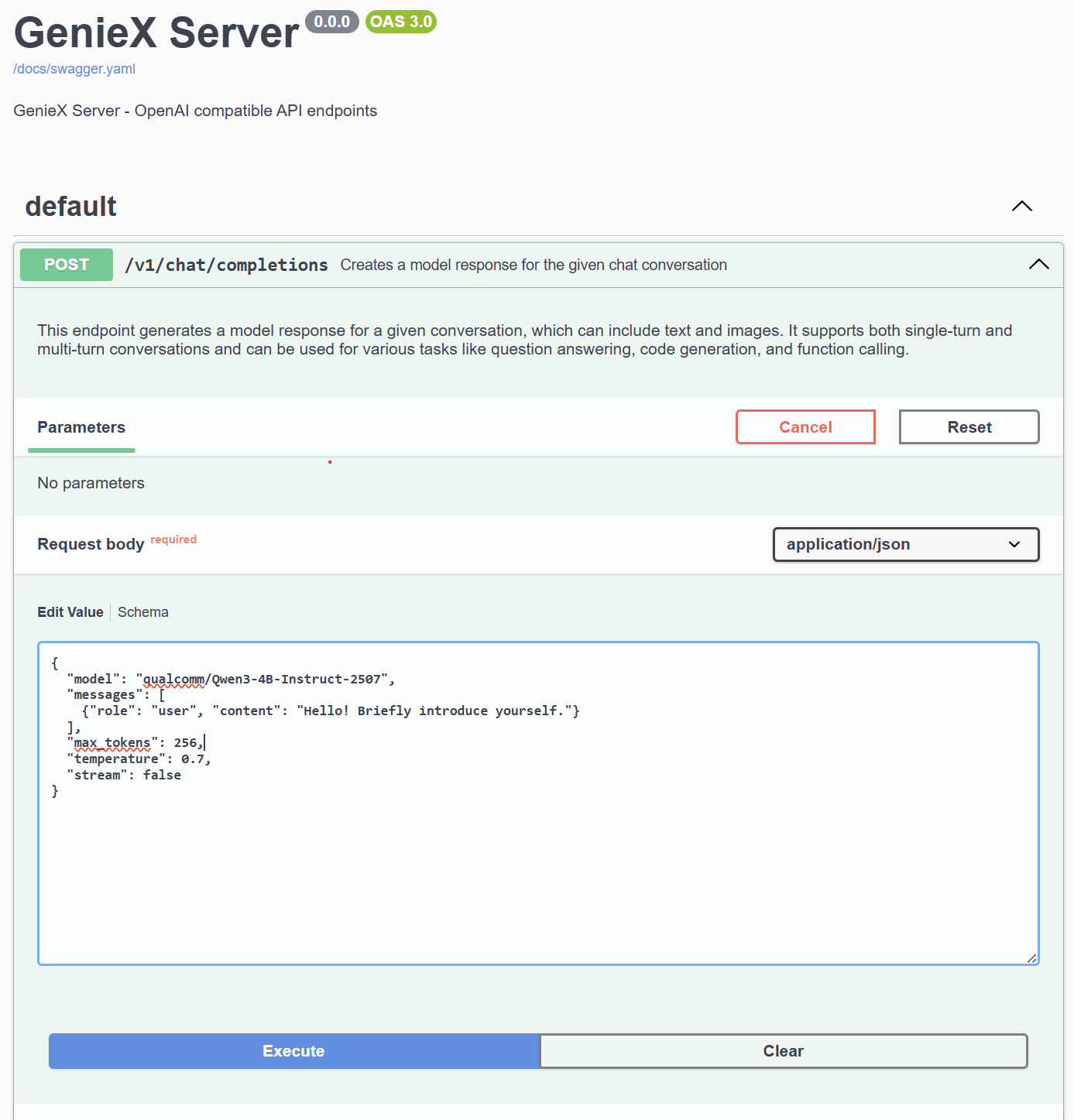
Example Value
通过 Swagger UI 试用
在浏览器中打开http://127.0.0.1:18181 即可访问内置的 Swagger UI。
步骤 1. 展开 POST/v1/chat/completions 端点,查看示例请求体与 schema。
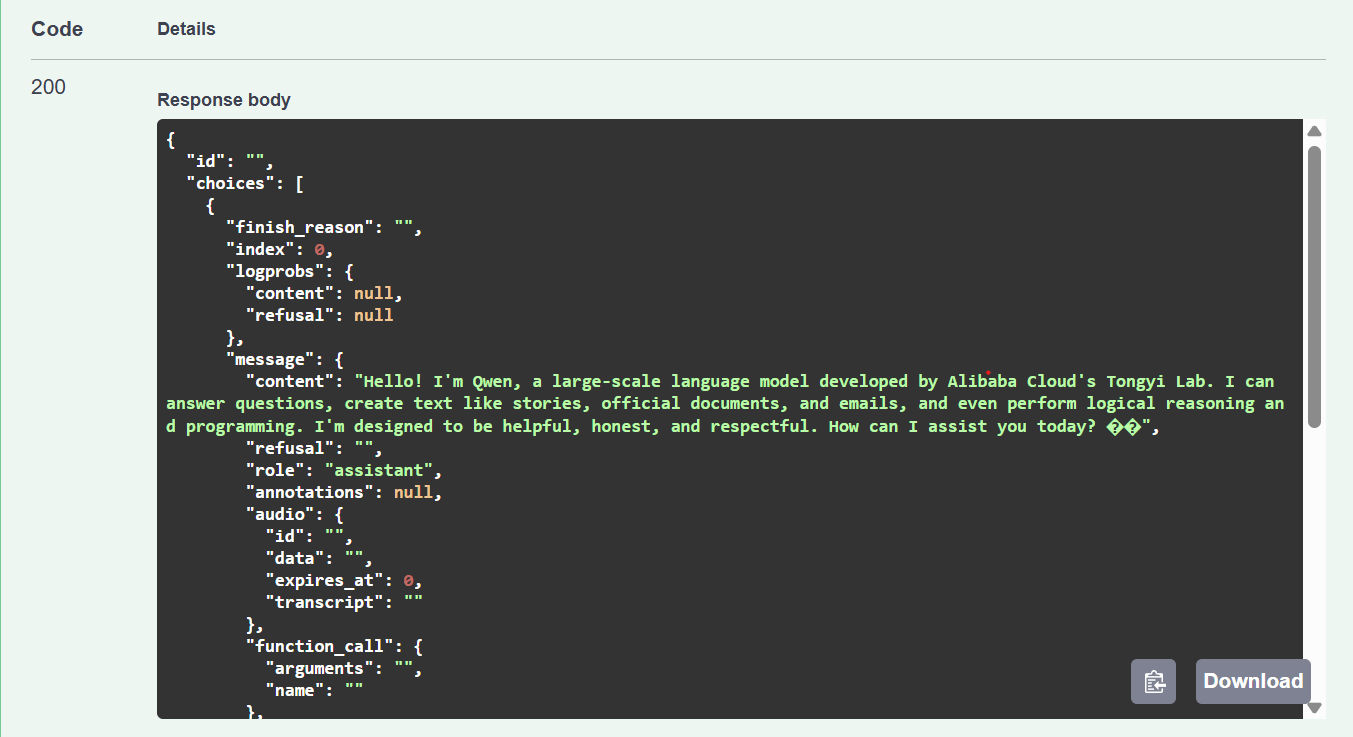
200 状态码以及模型生成的回复。
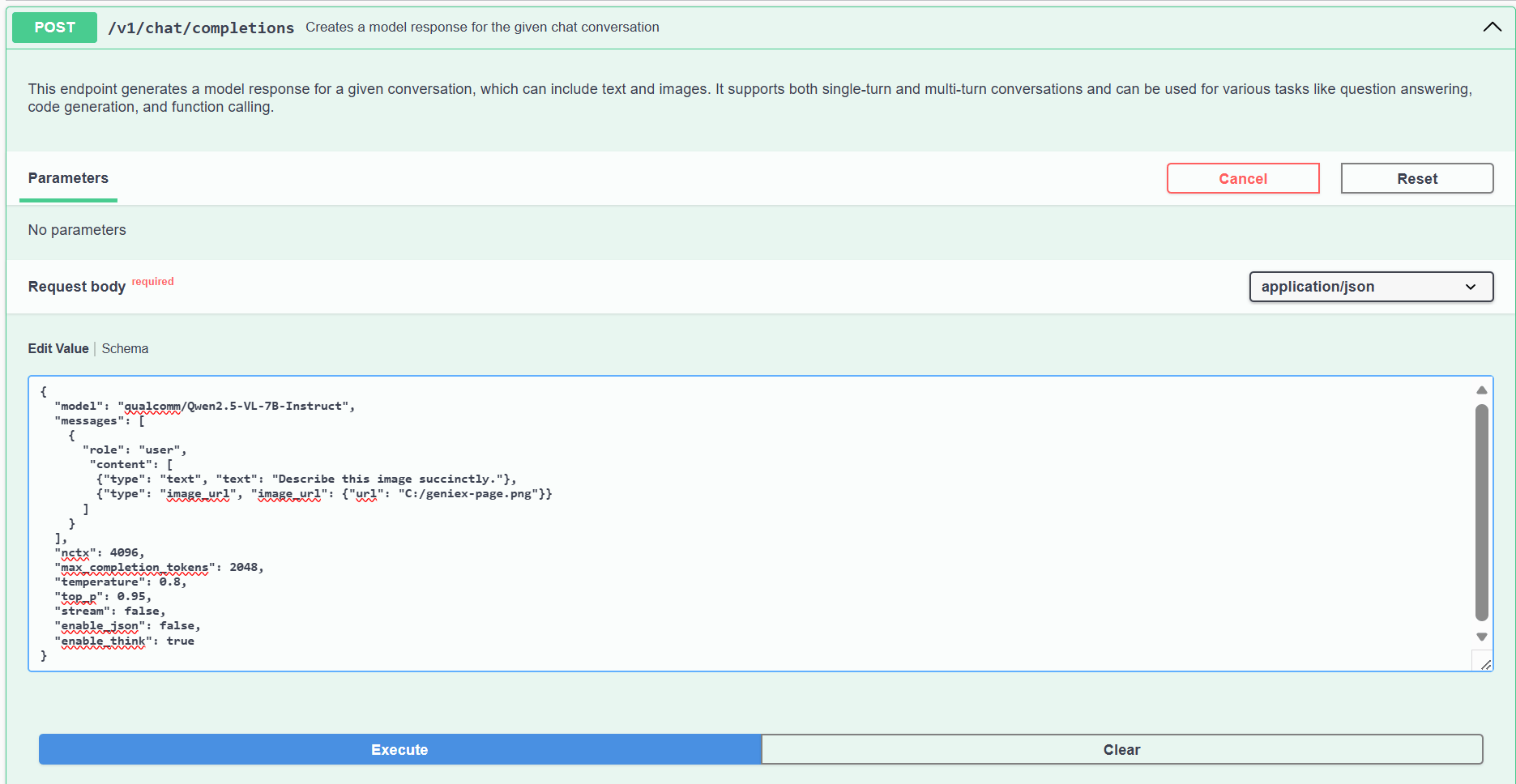
VLM 请求
image_url.url 支持三种格式:
| 格式 | 示例 |
|---|---|
本地文件路径(file:// 前缀可选) | C:/Users/Username/Pictures/photo.jpg、file:///tmp/photo.jpg |
| HTTP / HTTPS URL——由服务器拉取 | https://example.com/image.jpg |
| Base64 data URL——内联图像字节 | data:image/png;base64,iVBORw0KGgo... |
在 Docker 中运行? 本地路径会在容器内解析,而不是主机。安装命令已经把
$PWD/data 挂载到 /data——把图片放进去,然后传 /data/cat.jpg 即可。或者直接用 HTTP URL 或 base64 data URL,绕过文件系统。Example Value
image_url.url 指向本地图片,然后点击 Execute。
Python 客户端(OpenAI SDK)
由于服务器使用 OpenAI 协议,可直接将官方openai Python 客户端指向本地端点,复用任意已有的 OpenAI 代码。先通过 pip install openai 安装,然后:
python
请将
model 替换为已经拉取的模型。可选的 :<precision> 后缀用于选择精度(量化)变体(例如 Q4_0、Q4_K_M、Q8_0),Q4_0 推荐用于 Hexagon NPU 上的 llama.cpp。详见支持的精度(量化)。其他端点
GET /v1/models——列出可用模型。GET /v1/models/{model}——查询指定模型的信息。
Was this page helpful?