通用
GenieX 是什么?
GenieX 是什么?
面向高通骁龙的多平台 AI 推理 SDK。GenieX 在 Hexagon NPU、Adreno GPU 或 CPU 计算单元上端侧运行前沿 LLM 与 VLM,覆盖 Windows ARM64、Android 与 Linux ARM64。详见 GenieX 是什么。
应该选哪种接入方式?
应该选哪种接入方式?
- 试用、写脚本 —— Windows ARM64 或 Linux ARM64 上的 CLI。
- 构建应用 —— 本地服务器(兼容 OpenAI 协议的 HTTP)或 Python SDK。
- 移动端 —— Android SDK(Kotlin,Maven Central)。
- 可复现的 IoT 部署 —— Linux ARM64 EVK 上的 Docker 镜像,锁定到指定 release tag。
哪里能看到 GenieX 支持的硬件?
哪里能看到 GenieX 支持的硬件?
支持的平台 —— Windows ARM64 上的 骁龙 X、Android 上的骁龙 8 至尊版、Linux ARM64 上的跃龙 QCS9075。
运行环境
llama.cpp 与 Qualcomm AI Engine Direct 有什么区别?
llama.cpp 与 Qualcomm AI Engine Direct 有什么区别?
- llama.cpp —— 运行任意 GGUF 模型,支持 NPU/GPU/CPU 计算单元。最适合试用社区模型。
- Qualcomm® AI Engine Direct(
qairt)—— 运行 Qualcomm AI Hub 预编译模型,仅 NPU。当模型在 Qualcomm AI Hub 可用时,通常是最快路径。
默认运行环境是哪个?
默认运行环境是哪个?
如果不传计算单元:
llama_cpp默认hybrid(HTP + CPU 按张量调度——骁龙上的快速路径)。qairt默认npu。
gpt-oss 在 llama_cpp 下回退到 npu。应该选哪种精度(量化)?
应该选哪种精度(量化)?
llama.cpp 在骁龙 NPU 上请用
Q4_0——它在 Hexagon NPU 上支持最佳。Qualcomm AI Hub 模型已预量化——无需选择。详见支持的精度(量化)。模型
能运行 Hugging Face 上任意模型吗?
能运行 Hugging Face 上任意模型吗?
llama.cpp 运行环境可执行任意 GGUF 模型。详见运行 Hugging Face 上的 GGUF 模型。Qualcomm AI Engine Direct 需要预编译的 Qualcomm AI Hub 模型——新增模型需先在 C++ 侧注册。
如何为受限模型设置 Hugging Face 令牌?
如何为受限模型设置 Hugging Face 令牌?
部分 Hugging Face 模型需要你接受许可协议并进行身份验证。设置以下环境变量之一:
- Windows:
$env:HF_TOKEN = "hf_..."(或$env:GENIEX_HFTOKEN = "hf_...") - Linux:
export HF_TOKEN="hf_..."(或export GENIEX_HFTOKEN="hf_...")
huggingface-cli login 将令牌持久化到 ~/.cache/huggingface/token。优先级:GENIEX_HFTOKEN > HF_TOKEN > 令牌文件。在 huggingface.co/settings/tokens 获取令牌。完整设置步骤见设置 Hugging Face 令牌。受支持模型列表在哪里?
受支持模型列表在哪里?
模型 —— 按运行环境拆分(Qualcomm AI Engine Direct、llama.cpp)。
芯片与设备
必须用骁龙设备吗?
必须用骁龙设备吗?
是。GenieX 面向高通骁龙芯片——Hexagon NPU、Adreno GPU 与骁龙 ARM CPU 计算单元。不支持 x86 或非骁龙 ARM 设备。如手头无设备,可使用 Qualcomm Developer Cloud / Device Cloud。
我的 Qualcomm AI Hub 模型提示需要 NPU——能在 CPU 上跑吗?
我的 Qualcomm AI Hub 模型提示需要 NPU——能在 CPU 上跑吗?
不能。Qualcomm AI Engine Direct 设计上仅支持 NPU。
cpu 与 gpu 别名会被自动转为 NPU 并打印告警。如需 CPU/GPU 回退,请改用 llama.cpp 运行环境(GGUF 模型)。QDC(Qualcomm Device Cloud)
我必须有自己的 QDC 设备吗?
我必须有自己的 QDC 设备吗?
不需要。登录 Qualcomm Developer Cloud,选择一台骁龙设备,启动交互式会话——整个流程就是这样。关于哪些芯片在支持范围内,详见支持的平台。
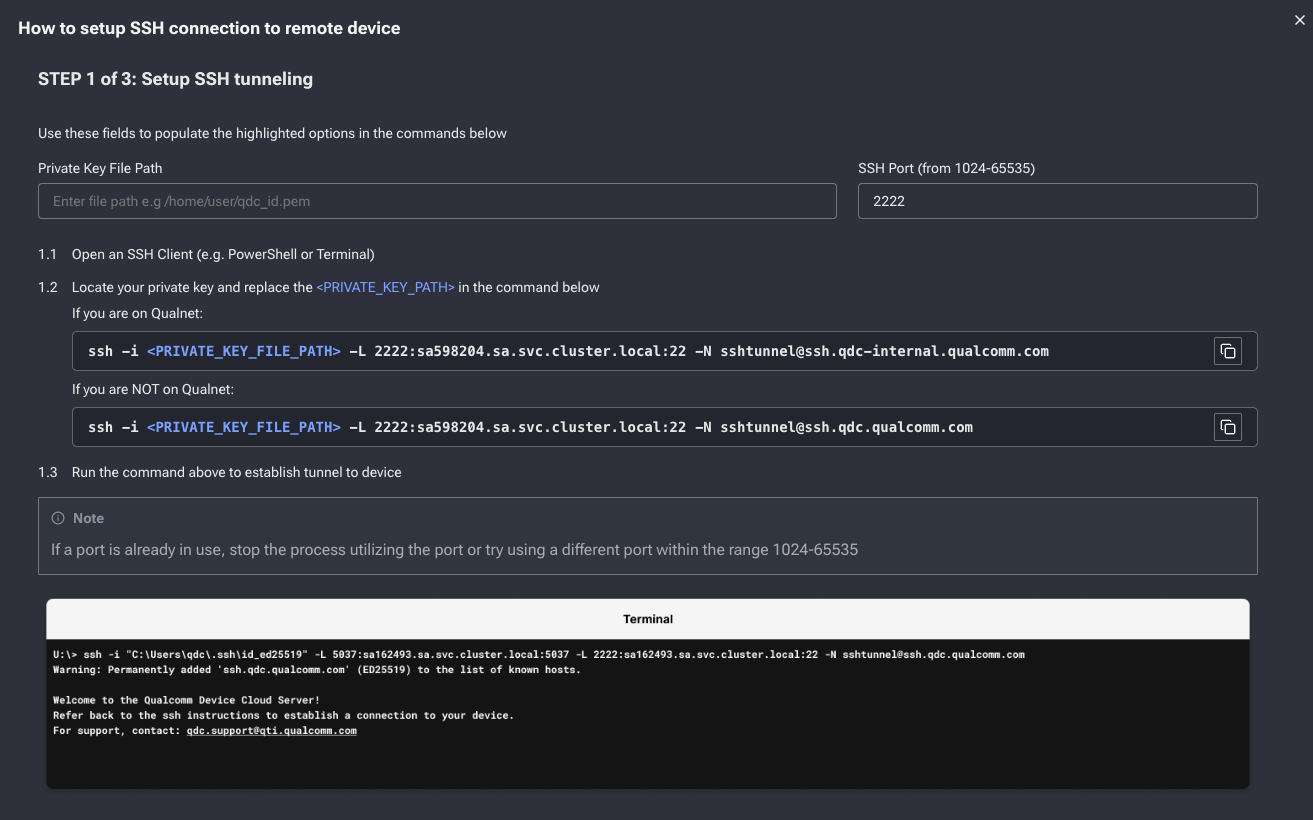
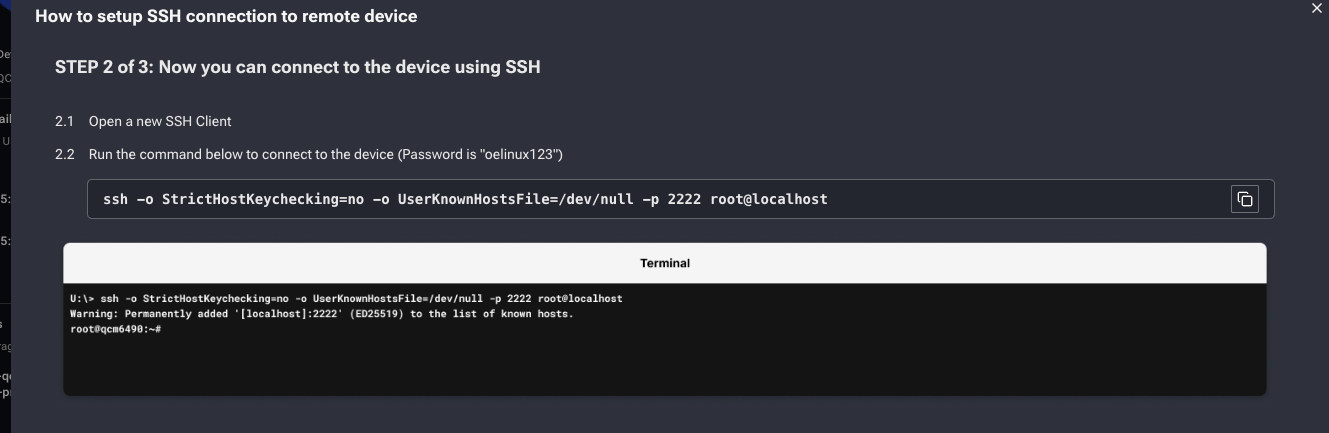
如何通过 SSH 连接到 QDC 设备?
如何通过 SSH 连接到 QDC 设备?
没有实体设备如何测试 Android demo?
没有实体设备如何测试 Android demo?
在 QDC 上使用 骁龙 8 Elite 或 8 Elite Gen 5 的交互式会话,并安装你从源码构建的 demo APK。从
qualcomm/ai-hub-apps 在 Android Studio 中构建示例应用(Build → Build APK(s))以生成 .apk。选择设备
登录 Qualcomm Device Cloud,选择 骁龙 8 Elite 或 骁龙 8 Elite Gen 5,并选择 Interactive session(交互式会话)。
Python
如何在 Linux ARM64 设备上安装 Python?
如何在 Linux ARM64 设备上安装 Python?
GenieX 要求 ARM64 Python,不支持 x86_64 / AMD64(即使在模拟器下也不支持)。QDC 设备(高通嵌入式 Linux / Yocto)已预装 ARM64 Python,用 方法 2 —— apt(仅 Ubuntu ARM64)QDC Yocto 镜像不带
python3 --version 验证即可。如设备未预装 Python,使用下列方法之一。方法 1 —— Miniconda(推荐;Yocto 与 Ubuntu ARM64 均可用)apt,请使用上面的 Miniconda 方法。Windows ARM64 是否支持 Miniconda?
Windows ARM64 是否支持 Miniconda?
不支持。目前 Miniconda 没有原生的 Windows ARM64 安装程序。请直接从 python.org 下载官方 Python 3.13.3 ARM64 安装程序——详见 Python 安装。不要安装 x86 / AMD64 版本:GenieX wheel 只支持 ARM64。
服务器 / API
本地服务器兼容 OpenAI 吗?
本地服务器兼容 OpenAI 吗?
是——详见本地服务器。可将官方
openai Python 客户端指向 http://127.0.0.1:18181/v1,OpenAI 代码无需修改即可复用。geniex serve 会自动下载模型吗?
geniex serve 会自动下载模型吗?
不会。请先用
geniex pull 拉取模型再启动服务器。Was this page helpful?