架构
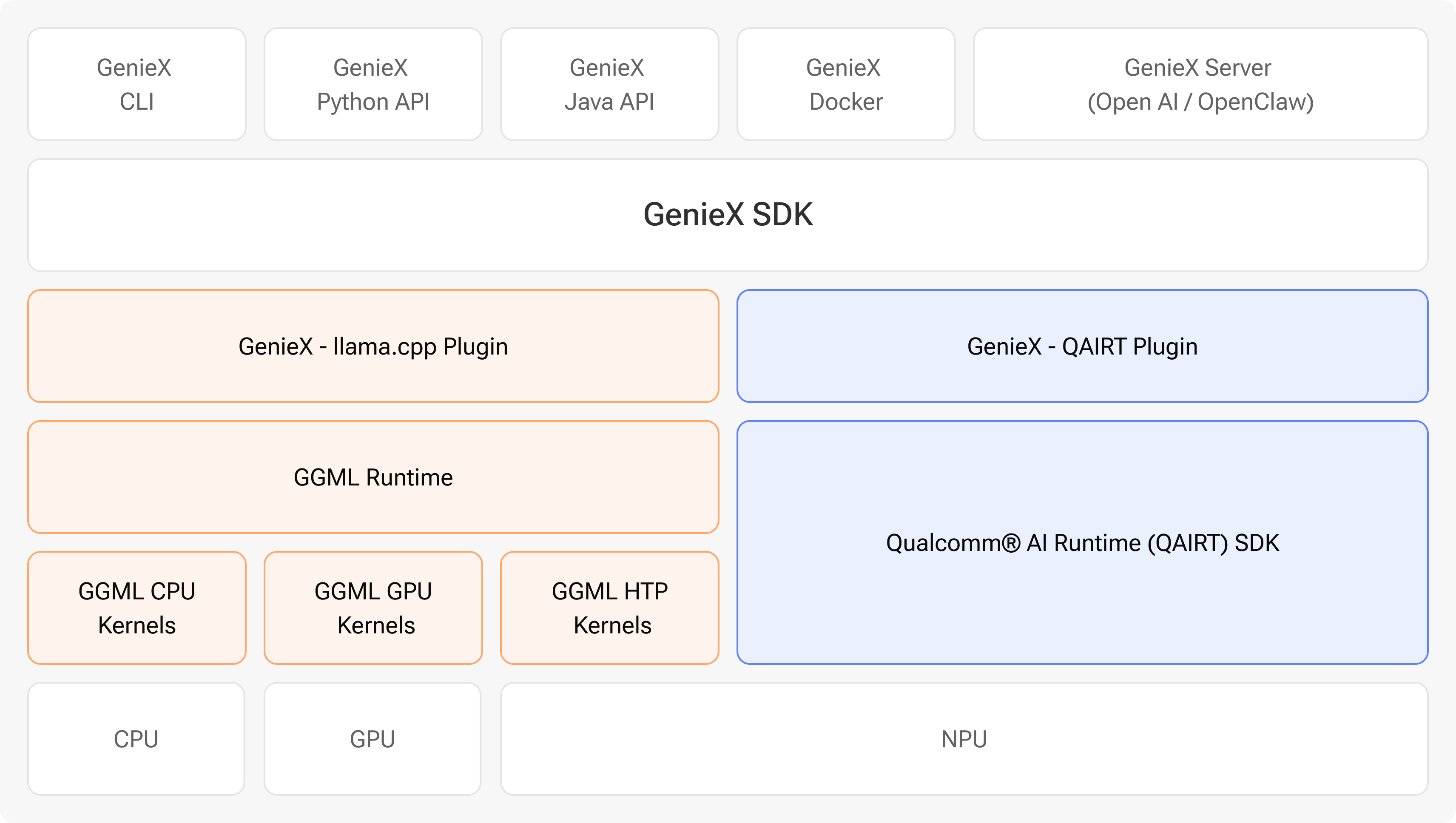
- CLI —— 直接从终端运行并提供模型服务。
- Python —— 通过 Python SDK 将推理嵌入你的应用。
- Java/Kotlin —— 面向端侧移动应用的 Android SDK。
- Docker —— 用于可复现部署的容器化镜像。
- 兼容 OpenAI 协议的服务器 —— 可直接替换、供现有 OpenAI 客户端使用的本地服务器。
Qualcomm AI Engine Direct 是官方名称,它也被称为 Qualcomm AI Engine Direct SDK、Qualcomm AI Runtime 以及 QAIRT。本文档中我们统一使用该官方名称。
为什么是两种运行环境?
这样你就能在同一套 SDK 中同时获得广泛的模型支持与最佳性能:- 大多数模型开箱即用 —— 通过 GenieX 推理 Hugging Face 上几乎任意 GGUF 模型,它即可通过 llama.cpp 在 CPU / GPU / NPU 上运行。
- Qualcomm® AI Hub 模型以最佳方式运行 —— 发布到 Qualcomm AI Hub 的模型已按芯片预编译,并通过 Qualcomm AI Engine Direct 在 Hexagon NPU 上运行,以获得端侧的峰值性能。
GenieX 能做什么
- 本地运行模型 —— 覆盖骁龙 X(Windows ARM64)、骁龙 8 至尊版(Android)以及跃龙 IoT 芯片。
- 选择运行环境 ——
llama.cpp适配任意社区 GGUF 模型,Qualcomm AI Engine Direct(qairt)适配 Qualcomm AI Hub 预编译的 NPU 模型包。 - 构建应用 —— 通过 CLI、兼容 OpenAI 协议的本地服务器、Python SDK、Android SDK 或 Docker 镜像。
从这里开始
快速入门
选择适合的接入方式,几分钟内完成首次推理。
平台与运行环境
GenieX 支持的骁龙平台,以及何时选 llama.cpp 或 Qualcomm AI Engine Direct。
模型
在 llama.cpp 与 Qualcomm AI Engine Direct 运行环境上经过验证的 LLM 与 VLM 模型。
社区
提交 Issue
在 GitHub 上提交 bug、需求或浏览开放的 Issue。
加入 Slack
与 GenieX 团队及其他开发者协作交流。
法律信息
许可证
GenieX 基于 BSD 3-Clause 许可证发布。
使用条款
Qualcomm 网站使用条款。
Was this page helpful?