Architecture
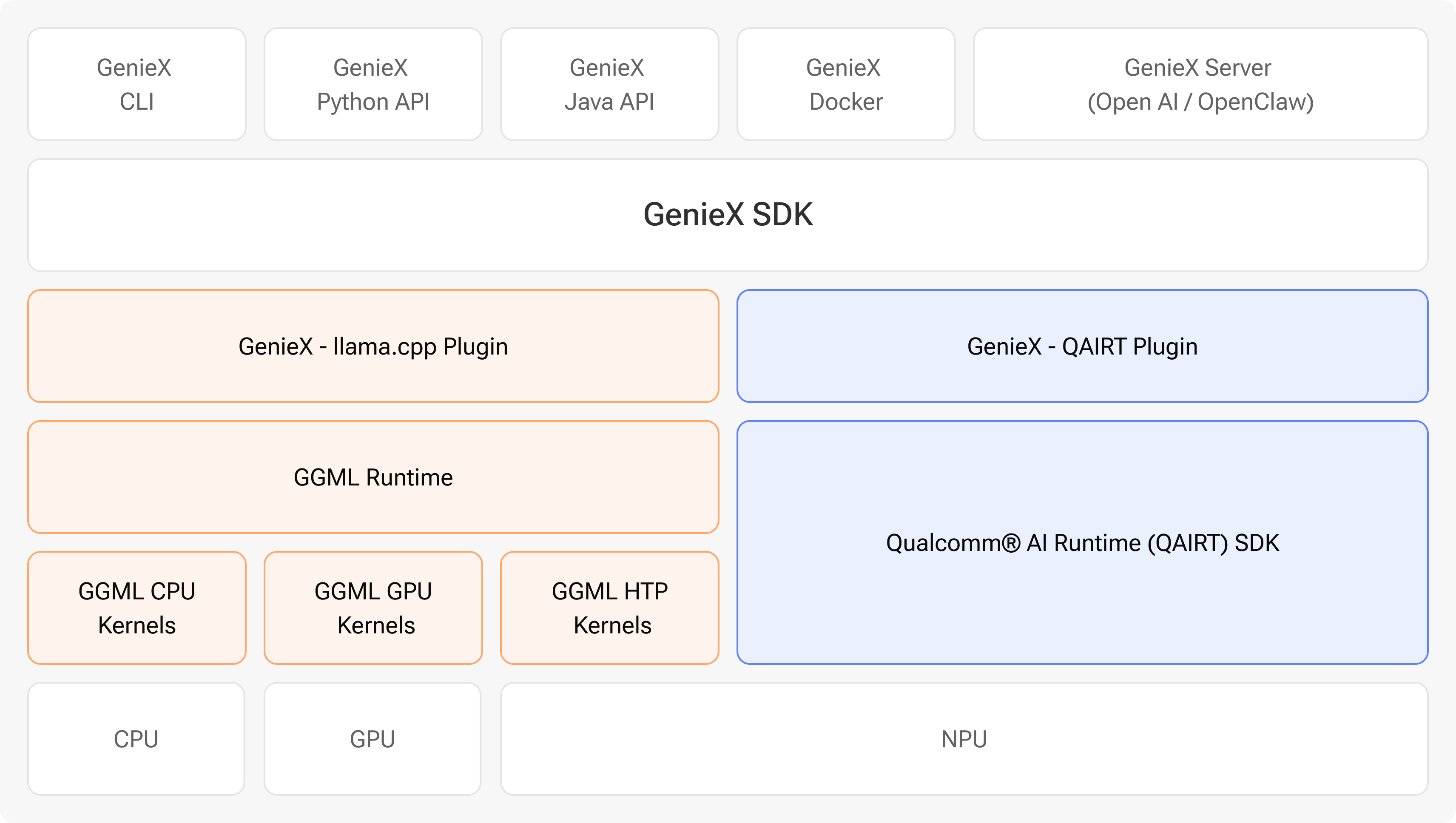
- CLI — run and serve models straight from the terminal.
- Python — embed inference in your apps with the Python SDK.
- Java/Kotlin — the Android SDK for on-device mobile apps.
- Docker — a containerized image for reproducible deployments.
- OpenAI-compatible server — a drop-in local server for existing OpenAI clients.
Qualcomm AI Engine Direct is the official name of what is also known as the Qualcomm AI Engine Direct SDK, Qualcomm AI Runtime, and QAIRT. Throughout these docs we use the official name.
Why two runtimes?
So you get both broad model coverage and optimal performance in one stack:- Most models just work — point GenieX at almost any GGUF on Hugging Face and it runs on CPU / GPU / NPU via llama.cpp.
- Qualcomm® AI Hub Models run optimally — models published to Qualcomm AI Hub are pre-compiled per chipset and run through Qualcomm AI Engine Direct on the Hexagon NPU for peak on-device performance.
What you can do with GenieX
- Run models locally on Snapdragon X (Windows ARM64), Snapdragon 8 Elite (Android), and Dragonwing IoT chipsets.
- Pick a runtime —
llama.cppfor any community GGUF model, Qualcomm AI Engine Direct (qairt) for Qualcomm AI Hub pre-compiled NPU bundles. - Build apps through the CLI, an OpenAI-compatible local server, the Python SDK, the Android SDK, or a Docker image.
Pick where to start
Quickstart
Choose your interface and get to first inference in minutes.
Platforms & runtimes
Snapdragon platforms GenieX supports, and when to pick llama.cpp vs Qualcomm AI Engine Direct.
Models
Tested LLMs and VLMs across the llama.cpp and Qualcomm AI Engine Direct runtimes.
Community
Report an issue
File a bug, request a feature, or browse open issues on GitHub.
Join Slack
Collaborate with the GenieX team and other developers.
Legal
License
GenieX is released under the BSD 3-Clause License.
Terms of Use
Qualcomm site terms of use.
Was this page helpful?